- Применение GAN для аугментации: революция в данных и машинном обучении
- Что такое GAN и как он работает?
- Почему применение GAN для аугментации данных столь важно?
- Преимущества использования GAN для аугментации
- Практические примеры использования GAN для аугментации
- Медицина
- Автономные транспортные средства
- Искусство и развлечения
- Недостатки и ограничения использования GAN в аугментации
- Как минимизировать риски
- Перспективы и будущее использования GAN в аугментации данных
Применение GAN для аугментации: революция в данных и машинном обучении
В современном мире, где данные играют ключевую роль в развитии технологий, особенно в области искусственного интеллекта и машинного обучения, появляется необходимость в создании больших объемов качественной информации. Однако, собрать достаточно данных для обучения моделей зачастую трудно, дорого и занимает много времени. Именно в этой ситуации на помощь приходят генеративные состязательные сети (GAN — Generative Adversarial Networks). Они позволяют не только создавать реалистичные изображения, звуки и видео, но и значительно расширять и улучшать наборы данных с помощью метода, известного как аугментация данных.
В этой статье мы подробно разберем, что такое GAN, как его применяют для аугментации данных, почему этот метод считается одним из самых перспективных в современном машинном обучении, и какие преимущества он дает в реальных приложениях. Также рассмотрим конкретные примеры использования, плюсы и минусы данного подхода, а завершением станет обсуждение перспектив развития этой технологии.
Что такое GAN и как он работает?
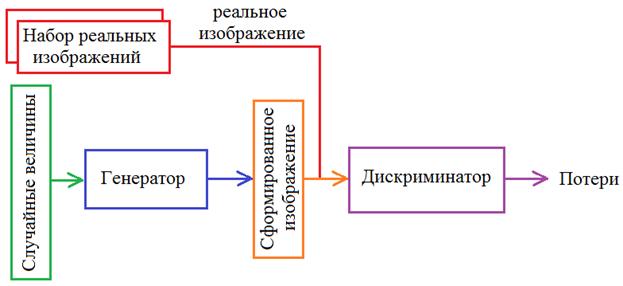
Генеративные состязательные сети (GAN), это тип нейронных сетей, предложенных в 2014 году исследователями Иэном Гудфеллоу и его коллегами. Их уникальность заключается в способности создавать настолько реалистичные изображения или другие типы данных, что их практически невозможно отличить от настоящих. Основная идея заключаеться в существовании двух конкурирующих нейронных сетей: генератора и дискриминатора.
Генератор отвечает за создание новых данных, идентичных оригиналу, а дискриминатор научен различать настоящие и сгенерированные образцы. В процессе обучения обе сети "сразаются" между собой, что приводит к тому, что в итоге генератор научится создавать данные, практически неотличимые от реальных. Вот, как это выглядит визуально:
| Компонент GAN | Описание |
|---|---|
| Генератор | Создает новые образцы данных на основе случайного шума, стремясь сделать их максимально похожими на реальные. |
| Дискриминатор | Обучен отличать реальные данные от искусственно созданных генератором. Постепенно он становится все более точным. |
После завершения процесса обучения генератор способен производить данные настолько правдоподобные, что их можно использовать в различных прикладных задачах — от развлечений до медицинской диагностики.
Почему применение GAN для аугментации данных столь важно?
Одной из главных проблем в машинном обучении является «большой разрыв» между количеством доступных данных и требованиями современных алгоритмов. Многие модели требуют миллионов аннотированных образцов для обучения, что часто невозможно по причине ограничения ресурсов или сложности сбора данных. В такой ситуации помогает аугментация данных — расширение существующего набора за счет дополнительных искусственно созданных образцов.
Генеративные состязательные сети предоставляют новый уровень возможностей для аугментации. Они позволяют создавать качественные, разнообразные и реалистичные новые образцы, которые идеально дополняют исходную выборку. Это особенно актуально в таких областях, как медицина (создание изображений редких заболеваний), автопромышленность (обучение систем распознавания объектов), и в сфере развлечений. Использование GAN для этой цели дает преимущество, возможность генерировать данные, которых раньше было невозможно получить, значительно ускоряя и удешевляя процесс обучения моделей.
Преимущества использования GAN для аугментации
- Высокая реалистичность — создаваемые изображения и данные выглядят настолько натурально, что их можно использовать в производственных системах без опасений.
- Разнообразие — GAN позволяют генерировать огромное количество вариантов, что помогает моделям лучше обучаться на различных сценариях.
- Экономия времени и ресурсов — значительно сокращают необходимость в сборе новых данных вручную.
- Обработка редких случаев, для труднодоступных или редких случаев, например, уникальных медицинских изображений, GAN обеспечивают дополнительный поток данных.
- Гибкость, модели могут обучаться для генерации изображений, звуков, текста или даже 3D-объектов, что делает подход универсальным.
Практические примеры использования GAN для аугментации
Рассмотрим ряд отраслей, где применение GAN становится настоящим прорывом, позволяя получать качественный материал для обучения систем без дополнительных затрат на сбор данных.
Медицина
Одним из наиболее важных применений GAN является медицина. Создание изображений редких заболеваний помогает подготовить системы автоматической диагностики даже тогда, когда у специалистов очень мало примеров для обучения. В частности, GAN используются для генерации ультразвуковых, рентгеновских или МРТ изображений, что существенно расширяет обучающую выборку.
| Пример | Описание |
|---|---|
| Генерация редких заболеваний | Создание синтетических изображений болезней, которые встречаются очень редко, для обучения диагностических моделей. |
| Улучшение качества данных | Обогащение существующих изображений мелкими деталями, увеличивающими качество распознавания. |
Автономные транспортные средства
В системах распознавания дорожных ситуаций важно иметь разнообразные примеры объектов — пешеходов, транспортных средств, дорожных знаков. GAN позволяют генерировать множество вариантов сцен, включая сложные погодные условия или необычное освещение, что помогает повысить надежность систем.
Искусство и развлечения
В мире кино, игр или дизайна GAN используются для быстрого создания прототипов, моделирования персонажей и генерации новой контента. Это не только ускоряет рабочие процессы, но и делает их более креативными.
Недостатки и ограничения использования GAN в аугментации
Несмотря на выдающиеся возможности, применение генеративных сетей в аугментации данных имеет и свои ограничения. Во-первых, обучение GAN — весьма сложный процесс, требующий много времени и вычислительных ресурсов. Во-вторых, иногда создаваемые модели изображения могут содержать аномалии или несовершенства, что снижает их эффективность при обучении. Также, есть риск появления «чувствительных» повторов или чрезмерной схожести между сгенерированными и исходными образцами, что отрицательно сказывается на расширении выборки.
Как минимизировать риски
- Правильная настройка модели, подбор параметров и архитектуры GAN, чтобы избежать переобучения и артефактов.
- Качественная проверка сгенерированных данных — использование автоматических и ручных методов оценки, чтобы исключить некачественный контент.
- Комбинированное обучение — дополнение сгенерированными данными реальной выборкой для повышения качества моделей.
Перспективы и будущее использования GAN в аугментации данных
Будущее технологий генерации данных невероятно яркое и многообещающее. В ближайшие годы мы можем ожидать появления всё более мощных и универсальных моделей GAN, которые смогут создавать сложно структурированные объекты, такие как 3D-анимированные сцены, видео или даже синтетические ученые базы данных. В области медицинских изображений уже сейчас ведутся разработки по использованию GAN для создания «тестовых» пациентов и имитации редких случаев, что значительно уменьшит барьер для внедрения автоматизированных диагностических систем.
Также в планах — объединение GAN с другими моделями, такими как автоэнкодеры или трансформеры, для повышения качества и разнообразия сгенерированных данных. Такой симбиоз откроет новые горизонты в сфере искусственного интеллекта, автоматической аналитики и образовательных технологий. Все больше компаний и научных институтов признают важность и эффективность использования GAN для расширения наборов данных, что будет способствовать развитию новых приложений и индустрий.
Применение GAN для аугментации данных — это одна из самых захватывающих и перспективных областей в современном искусственном интеллекте. Благодаря способности создавать очень реалистичные и разнообразные новые образцы, GAN существенно меняют подходы к подготовке обучающих выборок, существенно сокращая затраты и ускоряя развитие технологий. В будущем мы еще не раз услышим о новых прорывах, в которых генеративные сети займут центральное место в обеспечении качества и объема данных для машинного обучения.
Вопрос: Почему использование GAN для аугментации данных считаеться таким важным и перспективным направлением в области искусственного интеллекта?
Ответ: Использование GAN для аугментации данных позволяет создавать реалистичные, разнообразные и уникальные образцы, которых зачастую невозможно было бы получить естественным путем; Это значительно увеличивает объем и качество обучающей выборки, что повышает точность и надежность моделей без дорогостоящего и долгого сбора новых данных. В будущем эта технология обещает революционизировать передачу информации, обучение систем и создание контента, делая ИИ более универсальным и эффективным.
Подробнее
| аугментация данных | GAN в медицине | генеративные модели | применение GAN | будущее GAN |
| создание изображений | автономные системы | искусственная генерация | эффективность GAN | развитие технологий |
| синтетические данные | обучение модели | машинное обучение | ретушь изображений | автоматизация производства |
| разработка AI | потенциал AI | синтез контента | экспертные системы | области применения GAN |