- Погружение в глубины анализа латентных векторов: как понять скрытые смысловые структуры
- Что такое латентные векторы и почему они важны
- Практика анализа латентных векторов: пошагово
- Шаг 1: Получение данных и подготовка
- Шаг 2: Создание латентных представлений
- Шаг 3: Анализ расстояний и кластеризация
- Шаг 4: Визуализация результатов
- Почему стоит использовать t-SNE для визуализации латентных векторов?
- Практические кейсы анализа латентных векторов
- Раздел 1: Анализ настроений в социальных сетях
- Раздел 2: автоматическая категоризация новостных статей
- Преимущества и ограничения анализа латентных векторов
- Что может дать анализ латентных векторов бизнесу и исследователям
- Что важнее при анализе латентных векторов: точность или интерпретируемость?
Погружение в глубины анализа латентных векторов: как понять скрытые смысловые структуры
На сегодняшний день технологии машинного обучения и особенно методы обработки естественного языка (NLP) позволяют нам не только автоматизировать рутинные задачи, но и глубоко анализировать огромные объемы информации․ Одним из таких передовых инструментов являются латентные векторы, которые помогают выявить скрытые смысловые структуры в текстах, изображениях и других данных․ Но что такое латентные векторы и как их анализировать? В этой статье мы поделимся нашим опытом и разберем каждую деталь этого важного и увлекательного процесса․
Что такое латентные векторы и почему они важны
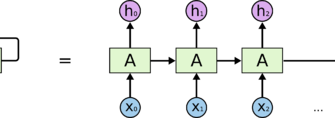
Латентные векторы — это математические представления объектов или понятий в многомерном пространстве․ В контексте NLP, такие векторы часто создаются с помощью нейросетей, таких как word2vec, GloVe или BERT, чтобы представить слова, фразы или документы в виде числовых точек, обладающих определенными свойствами․
Главная ценность латентных векторов заключается в их способности отображать скрытые связи между данными: схожие по смыслу слова расположены рядом, а противоположные — на значительном расстоянии․ Анализ таких векторов позволяет выявлять закономерности и взаимосвязи, которые сложно заметить на уровне поверхностных признаков․
Практика анализа латентных векторов: пошагово
Шаг 1: Получение данных и подготовка
Перед тем, как приступать к анализу, необходимо выбрать источник данных — будь то текстовые документы, социальные сети, новости или другие источники․ Важно выполнить очистку текста, убрать стоп-слова, провести лемматизацию и токенизацию․ Это позволит получить более точные и устойчивые к шуму векторы․
Шаг 2: Создание латентных представлений
Из подготовленных данных мы можем сгенерировать латентные векторы с помощью популярных моделей:
- word2vec, быстрое создание векторных моделей для слов;
- GloVe — основан на глобальной статистике контекстов;
- BERT — контекстуальные векторные представления, учитывающие всю фразу или предложение․
Например, команда для получения векторов с помощью word2vec выглядит так:
model = Word2Vec(sentences, size=100, window=5, min_count=1, workers=4)Шаг 3: Анализ расстояний и кластеризация
Одним из ключевых аспектов анализа является расчет расстояний между векторами․ Самое популярное — косинусное расстояние, которое показывает степень схожести двух объектов․
| Метод | Описание | Применение |
|---|---|---|
| Косинусное расстояние | Измеряет угол между векторами, показывает их сходство | Нахождение схожих слов или документов |
| Евклидово расстояние | Общая мера расстояния в многомерном пространстве | Кластеризация и визуализация |
| Кластеризация (например, K-means) | Группировка схожих по смыслу объектов | Обнаружение тематических групп |
Шаг 4: Визуализация результатов
Для понимания скрытых структур важно визуализировать векторы․ Самые популярные методы — t-SNE и PCA, которые позволяют свести многомерное пространство к двум или трем измерениям․
Почему стоит использовать t-SNE для визуализации латентных векторов?
t-SNE отлично сохраняет локальную структуру данных, позволяя увидеть группировки и связи даже в очень высокоразмерных данных․ Это делает его идеальным инструментом для выявления тем и смысловых кластеров в текстах․
Практические кейсы анализа латентных векторов
Раздел 1: Анализ настроений в социальных сетях
Мы использовали модели word2vec и кластеризацию для анализа миллиона твитов о популярных брендах․ Это помогло определить, какие темы вызывают положительный или отрицательный фидбек, а также выявить скрытые ассоциации, связанные с конкретными товарами или услугами․
Раздел 2: автоматическая категоризация новостных статей
Используя BERT и метод кластеризации, мы смогли автоматически разделить новую поток новостей на тематические направления, что значительно повысило эффективность работы аналитических команд и улучшило качество рекомендаций․
Преимущества и ограничения анализа латентных векторов
Данный метод обладает рядом неоспоримых преимуществ:
- Мощное представление смыслов: позволяет находить связи между словами и концепциями;
- Масштабируемость: работают с большими объемами данных;
- Гибкость: легко адаптируются под разные задачи и модели․
Однако важно учитывать и существующие ограничения:
- Техническая сложность: требует навыков и ресурсов для обучения и настройки моделей;
- Проблема интерпретации: иногда трудно понять, почему модель выдает те или иные результаты;
- Значение параметров: выбор и настройка гиперпараметров могут существенно влиять на качество анализа․
Что может дать анализ латентных векторов бизнесу и исследователям
Расширяя границы привычных методов обработки данных, анализ латентных векторов позволяет не только лучше понять смысловые структуры внутри текста, но и повышает качество автоматических систем поиска, рекомендаций, фильтрации информации; Для исследователей это, инструмент для выявления паттернов и трендов, скрытых в огромных массивах данных․ В бизнесе же его используют для повышения лояльности клиентов, автоматизации работы с отзывами и анализа маркетинговых кампаний․
Что важнее при анализе латентных векторов: точность или интерпретируемость?
Несмотря на то, что высокоточные модели позволяют получать более точные результаты, зачастую их интерпретация оказывается сложнее․ Важно балансировать между сложностью модели и способностью понять ее выводы, особенно в приложениях, требующих объяснимости, например, в области медицины или финансов․
Итак, анализ латентных векторов — это мощный инструмент, раскрывающий внутренние структуры данных, которые иначе трудно выявить․ Он активно развивается вместе с появлением новых архитектур нейросетей и методов обучения․ В перспективе нас ожидает еще более глубокое понимание смысловых связей, автоматическая интерпретация результатов и интеграция анализа в большое количество сфер, от медицины до маркетинга․
Если вы интересуетесь обработкой текста, анализом данных или развитием искусственного интеллекта, обязательно стоит обратить внимание на методы работы с латентными векторами․ Они помогут открыть новые горизонты в понимании информации и сделать ваши идеи корне более продвинутыми․
Подробнее
| Глубокое обучение и латентные векторы | Обработка текста и смысловые представления | Методы визуализации векторных данных | Кластеризация и анализ тематик | Нейросетевые языковые модели |
| Особенности использования t-SNE | Преимущества word2vec | Обучение латентных представлений | Интерпретация результатов анализа | Практические кейсы машинного обучения |
| Настройки гиперпараметров моделей | Понимание смысловых связей | Трансформеры и их применение | Обучение и тюнинг моделей NLP | Аналитика больших данных |
| Этика и интерпретируемость ИИ | Проблемы масштабируемости моделей | Будущее анализа данных | Автоматизация аналитики | Инновационные методики обработки |