- Как применить генеративные состязательные сети (GAN) для эффективной аугментации данных
- Что такое GAN и почему они важны для аугментации данных
- Основные преимущества использования GAN для аугментации данных
- Практическое применение GAN для аугментации: пошаговая инструкция
- Этап 1: подготовка исходных данных
- Этап 2: обучение GAN
- Этап 3: генерация и проверка данных
- Можно ли полностью доверять сгенерированным данным?
Как применить генеративные состязательные сети (GAN) для эффективной аугментации данных
В современном мире машинного обучения и искусственного интеллекта качество и количество данных являются ключевыми факторами успеха любого проекта․ Но что делать‚ когда реальные данные ограничены или их трудно получить? Об этом мы подробно поговорим сегодня, о применении генеративных состязательных сетей (GAN) для расширения и обогащения набора данных․ Мы поделимся нашим опытом и практическими рекомендациями‚ расскажем‚ какими преимуществами обладает этот метод и как его реализовать в своих проектах․
Что такое GAN и почему они важны для аугментации данных
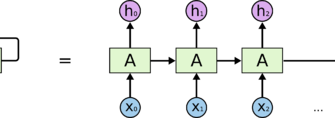
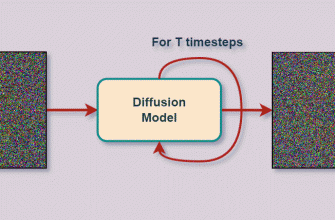
Генеративные состязательные сети (GAN‚ от англ․ Generative Adversarial Networks) — это тип нейросетей‚ который был представлен в 2014 году и с тех пор стал одним из самых известных и востребованных инструментов в области генерации искусственных данных․ Идея заключается в том‚ чтобы обучить две модели: генератор и дискриминатор․ Генератор создает новые изображения‚ похожие на реальные‚ а дискриминатор учится распознавать поддельные изображения от настоящих․ В процессе обучения обе модели "соревнуются"‚ что способствует созданию очень реалистичных образов․ Иметь возможность создавать похожую‚ но уникальную информацию — огромная ценность для расширения данных․
Для задач компьютерного зрения‚ медицинской диагностики‚ распознавания лиц и даже генерации новых текстур и объектов GAN стали практически незаменимым инструментом․ Они помогают не только преодолеть проблему нехватки данных‚ но и повышают устойчивость моделей к переобучению‚ обеспечивая больше вариативности и разнообразия входных данных․
Основные преимущества использования GAN для аугментации данных
- Увеличение объема данных․ Генерация дополнительных выборок‚ которые почти неотличимы от реальных изображений․
- Разнообразие и вариативность․ Создаваемые изображения могут выводить новые особенности и характеристики‚ помогающие модели учиться более обобщенно․
- Обработка данных с малыми наборами․ В случае‚ когда исходных данных слишком мало‚ GAN позволяют значительно расширить выборки․
- Контроль качества сгенерированного контента․ Современные методы позволяют сгенерировать изображения высокой четкости и реалистичности․
- Обеспечение конфиденциальности․ Можно создавать похожие‚ но искусственные данные‚ что особенно важно в медицинской сфере и при работе с чувствительной информацией․
Практическое применение GAN для аугментации: пошаговая инструкция
Теперь давайте расскажем о практическом опыте и разберем‚ как использовать GAN для расширения данных на конкретных примерах․ Этот процесс включает несколько этапов: подготовка данных‚ обучение модели‚ генерация новых образцов и их проверка․
Этап 1: подготовка исходных данных
Перед обучением GAN важно подготовить хорошо размеченные и репрезентативные выборки․ Чем лучше исходные данные‚ тем качественнее и реалистичнее будут сгенерированные изображения․ Необходимо убедиться‚ что все изображения имеют одинаковый размер и формат‚ а также выполнить предварительную обработку: нормализацию‚ вырезание ненужных элементов и балансировку классов․
Этап 2: обучение GAN
Обучение GAN — кропотливый процесс‚ требующий аккуратного выбора архитектуры и гиперпараметров․ Как правило‚ используют популярные реализации‚ такие как StyleGAN‚ CycleGAN или DCGAN‚ в зависимости от задачи и типа данных․
| Ключевые параметры | Описание |
|---|---|
| Размер латентного пространства | Объем вектора‚ из которого генерируется изображение․ Обычно выбирается в диапазоне 100-512 вариантов․ |
| Количество эпох обучения | Число проходов по датасету․ Чем больше‚ тем лучше результат‚ но важно следить за переобучением․ |
| Оптимизаторы | Часто используют Adam или RMSprop для достижения стабильных результатов․ |
Этап 3: генерация и проверка данных
После обучения модели самое время приступить к генерации новых изображений․ Здесь важно выбрать правильное количество — не слишком мало‚ чтобы было разнообразие‚ и не слишком много‚ чтобы не засорять выборки дубликатами․ Далее проводится их ручная или автоматическая проверка: смотрим‚ насколько реалистичны изображения‚ есть ли артефакты и соответствуют ли они заданным характеристикам․
"Использование GAN для аугментации данных — это не только способ увеличить выборки‚ но и возможность создавать новые‚ уникальные примеры‚ которые помогают моделям лучше обобщать информацию и достигать более высокой точности․"
Можно ли полностью доверять сгенерированным данным?
Конечно‚ вопрос о качестве и надежности искусственно созданных данных очень важен․ Несмотря на высокие показатели реалистичности современных GAN‚ иногда могут появляться артефакты или искажения․ Поэтому всегда нужно делать качественную проверку сгенерированных образцов и тестировать их на конечных задачах․ Иногда целесообразно совмещать реальные и искусственные данные в разной пропорции‚ чтобы добиться оптимальных результатов․
"Никогда не забывайте‚ что генерация данных — всего лишь инструмент․ Его правильное применение зависит от контекста задачи и качества исходных данных․"
Использование GAN для аугментации — это мощный и перспективный метод‚ который продолжает активно развиваться․ Современные модели становятся все более стабильными и универсальными‚ расширяя границы возможного в области искусственного создания данных․ В будущем можно ожидать появления еще более совершенных генераторов‚ способных создавать объемные модели‚ видео и даже 3D-объекты‚ что откроет новые горизонты для обучения нейросетей в сложных и разнообразных задачах․
Для тех‚ кто только начинает свой путь в использовании ГАН‚ важно помнить о необходимости тщательного отбора и проверки данных‚ постоянного мониторинга обучения и экспериментов с архитектурой․ Не бойтесь ошибаться и пробовать новые подходы — именно так можно добиться лучших результатов и найти собственные уникальные решения․
Подробнее
| LSI Запрос №1 | LSI Запрос №2 | LSI Запрос №3 | LSI Запрос №4 | LSI Запрос №5 |
|---|---|---|---|---|
| Что такое GAN и зачем они нужны для аугментации данных | Обучение генеративных состязательных сетей | Практические советы по использованию GAN | Преимущества аугментации с помощью GAN | Риски и ограничения использования GAN для генерации данных |
| Как увеличить объем данных с помощью GAN | Обучение GAN: этапы и основные параметры | Лучшие архитектуры GAN для аугментации | Проверка качества сгенерированных данных | Использование GAN в медицинской сфере |