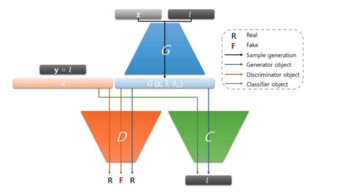
- Использование Generative Adversarial Networks (GAN) для расширения данных: революционный подход к повышению эффективности моделей AI
- Что такое GAN и как они работают?
- Основные этапы работы GAN
- Применение GAN для аугментации данных в различных сферах
- Компьютерное зрение и изображение
- Обработка естественного языка (NLP)
- Дополнительные области применения
- Преимущества использования GAN для аугментации данных
- Возможные ограничения и риски
- Практические советы по применению GAN для аугментации
- Пример использования GAN в проекте
Использование Generative Adversarial Networks (GAN) для расширения данных: революционный подход к повышению эффективности моделей AI
В современном мире технологий искусственного интеллекта одним из ключевых вызовов остается недостаток качественных и разнообразных данных․ Многие проекты сталкиваются с проблемой ограниченного объема обучающей выборки, что негативно сказывается на точности и надежности моделей машинного обучения․ Именно здесь на сцену выходит методика, которая за последние годы зарекомендовала себя как одна из наиболее перспективных — GAN (Generative Adversarial Networks), или сети с состязательными генераторами․
Использование GAN для аугментации данных позволяет создавать реалистичные, качественные и разнообразные изображения, текст и даже аудио․ Эта технология позволяет искусственно расширять объем данных, имитируя реальные образцы․ В этой статье мы подробно рассмотрим, что такое GAN, как они работают, и каким образом их можно применить для аугментации данных в различных сферах, от компьютерного зрения до обработки естественного языка․ Мы расскажем о преимуществах и возможных ограничениях, а также поделимся конкретными примерами успешных кейсов применения этой передовой технологии․
Что такое GAN и как они работают?
GAN, или Generative Adversarial Network, — это тип нейросетевой архитектуры, предложенной в 2014 году Иэном Гудфеллоу и его коллегами․ Эта система состоит из двух основных компонентов: генератора и дискриминатора․ Каждый из них обучается одновременно, состязаясь друг с другом, отсюда и название «состязательная сеть»․
Генератор — это модель, которая создает новые образцы данных, стремясь сделать их максимально похожими на реальные․ Дискриминатор — это модель, которая анализирует входные образцы и определяет, являются ли они подлинными (реальными) или созданными генератором․ Обучая эти две сети совместно, мы получаем систему, которая в процессе тренировки «учится» создавать очень реалистичные образцы, практически неотличимые от настоящих․
Основные этапы работы GAN
- Обучение генератора: Он получает случайный шум как вход и старается превратить его в такой образец данных, который сможет обмануть дискриминатор․
- Обучение дискриминатора: Он анализирует реальные образцы из обучающей выборки и созданные генератором, стараясь правильно классифицировать их․
- Обновление весов сетей: На каждом этапе веса обеих сетей корректируются на основе ошибок, что ведет к постепенному улучшению производительности․
В результате этого процесса генератор учится создавать все более правдоподобные образцы, а дискриминатор, все лучше распознавать подделки․ В итоге мы получаем систему, способную порождать новые, высококачественные данные без необходимости собирать их вручную․
Применение GAN для аугментации данных в различных сферах
Использование GAN для расширения обучающих данных особенно актуально в тех случаях, когда реальных образцов небольшое количество или их трудно получить․ Ниже приведены ключевые области, в которых эта технология уже доказала свою эффективность․
Компьютерное зрение и изображение
В области компьютерного зрения GAN применяются для создания новых изображений с целью увеличения датасетов, что позволяет повысить точность распознавания объектов, сегментации и классификации․
| Примеры использования | Описание |
|---|---|
| Повышение разнообразия данных | Создание вариаций изображений объектов, например, изменение позы, освещения, фона, что помогает моделям лучше учиться распознавать объекты в различных условиях․ |
| Реализация задач сегментации | Генерация аннотированных изображений для обучения, что значительно экономит время и ресурсы специалистам․ |
| Обработка медицинских изображений | Создание дополнительных медицинских изображений для обучения, например, для диагностики рака, что помогает бороться с ограниченностью данных из-за конфиденциальности или редкости случаев․ |
Обработка естественного языка (NLP)
В сфере обработки текстов GAN используются для синтеза новых текстовых данных, расширения датасетов для задач машинного перевода, анализа тональности, генерации статей и диалоговых систем․
| Примеры использования | Описание |
|---|---|
| Генерация текстов | Создание дополнительных примеров текстов для обучения моделей, чтобы повысить их устойчивость и качество․ |
| Обогащение языковых моделей | Увеличение объема данных для обучения, что позволяет моделям лучше понимать контекст и нюансы языка․ |
| Диалоговые системы | Создание виртуальных собеседников для тренировки и тестирования чат-ботов и виртуальных ассистентов․ |
Дополнительные области применения
Кроме компьютерного зрения и NLP, GAN активно применяются в области генерации музыки, видеоигр, в создании арта и разработки новых материалов (например, дизайна одежды или промышленного дизайна)․
| Область | Краткое описание |
|---|---|
| Генерация музыки | Создание новых музыкальных фрагментов на основе обучающих образцов, что способствует развитию музыкальной индустрии и автоматизации творчества․ |
| Создание виртуальных персонажей и арта | Генерация уникальных изображений и иллюстраций для видеоигр и фильмов․ |
| Дизайн и мода | Автоматическая генерация новых концептов одежды, аксессуаров и элементов интерьера․ |
Преимущества использования GAN для аугментации данных
Методика аугментации данных с помощью GAN имеет ряд очевидных преимуществ, которые делают ее особенно привлекательной для исследователей и практиков:
- Высокая реалистичность: Создаваемые сети образцы практически неотличимы от реальных данных, что существенно повышает качество обучающих выборок․
- Расширение данных при минимальных затратных ресурсах: В отличие от сбора новых данных, генерация с помощью GAN является более быстрым и дешевым процессом․
- Вариативность: Генерация разнообразных образцов помогает модели обучаться более устойчиво и избегать переобучения․
- Гибкость: GAN можно адаптировать под разные типы данных — изображения, текст, музыку и др․
Возможные ограничения и риски
Несмотря на очевидные преимущества, использование GAN для аугментации данных сопровождается определенными рисками и ограничениями:
- Проблема качества и Diversity: Иногда сгенерированные образцы могут быть не очень разнообразными или содержать артефакты, которые могут ухудшить обучение модели, особенно при неправильной настройке․
- Обучение требует ресурсов: Обучение GAN — это сложный и ресурсоемкий процесс, требующий мощных вычислительных ресурсов и специальных знаний․
- Риск создания «фальшивых» данных: В некоторых случаях сгенерированные данные могут вводить в заблуждение или не соответствовать реальности, что негативно скажется на конечных результатах․
- Этические и правовые аспекты: Использование искусственно сгенерированных данных может вызвать вопросы касательно авторских прав и доверия к моделям․
Практические советы по применению GAN для аугментации
Чтобы успешно реализовать аугментацию с помощью GAN, важно учитывать несколько ключевых аспектов:
- Выбор архитектуры GAN: В зависимости от задач подбирается подходящая модель — Deep Convolutional GAN (DCGAN), StyleGAN, CycleGAN и др․
- Подготовка данных: Для обучения GAN необходимо иметь хотя бы небольшую, но качественную и разнородную набросочную выборку․
- Настройка гиперпараметров: В процессе тренировки важно правильно выбрать скорость обучения, размер батча, количество эпох и другие параметры․
- Оценка качества сгенерированных данных: Используются метрики, такие как Inception Score или Frechet Inception Distance (FID), для оценки реалистичности и разнообразия образцов․
- Интеграция в pipeline: Сгенерированные данные должны быть тщательно проверены и протестированы перед использованием в обучении конечных моделей․
Пример использования GAN в проекте
Представим ситуацию, что мы работаем над проектом по распознаванию редких заболеваний по медицинским изображениям․ Обучающая выборка ограничена, и модели не достигают нужной точности․ Для решения этой задачи мы обучили StyleGAN создавать новые медицинские изображения в тех же форматах и с похожими аннотациями․ После оценки качества с помощью FID мы добавили сгенерированные изображения в основную выборку, что позволило повысить точность модели и снизить число ошибок․
Использование Generative Adversarial Networks для аугментации данных — это мощный инструмент, способный существенно повысить эффективность обучения моделей машинного интеллекта․ Они дают возможность создавать качественные, разнообразные и реалистичные образцы, что особенно важно в ситуациях с ограниченной выборкой․ Однако не стоит недооценивать сложности процесса, связанные с настройкой, обучением и проверкой качества сгенерированных данных․
Для достижения лучших результатов важно внимательно подбирать архитектуру GAN, проводить тщательную оценку качества и учитывать возможные риски․ Современные исследования и практические кейсы показывают, что при правильном использовании эта технология станет незаменимым помощником для разработки более точных и устойчивых моделей AI — не только расширяя выбор данных, но и открывая новые горизонты в создании контента в цифровом пространстве․
Вопрос: Почему важно использовать GAN для аугментации данных и какие преимущества это дает?
Использование GAN для аугментации данных важно потому, что оно позволяет создавать качественные и разнообразные обучающие образцы, что значительно повышает эффективность и точность моделей машинного обучения․ Преимущества включают в себя уменьшение необходимости сбора новых данных, а также возможность запускать обучение при ограниченных ресурсах․ Кроме того, с помощью GAN можно имитировать различные сценарии и условия, что помогает моделям стать более устойчивыми и адаптивными к реальным ситуациям․
Подробнее
| Image augmentation | Использование GAN для увеличения объема изображений в датасетах | Medical image synthesis | Создание дополнительных медицинских изображений для обучения | Text data augmentation | Генерация новых текстовых данных для NLP задач |
| StyleGAN applications | Создание фотореалистичных изображений для различных отраслей | Data augmentation in speech recognition | Расширение аудиоданных для распознавания речи | Art and content creation | Генерация оригинальных визуальных и музыкальных материалов |