- Генерация видео через рекуррентные нейронные сети: секреты искусственного творчества
- Что такое рекуррентные нейронные сети и почему они важны для генерации видео
- Основные типы RNN для генерации видео
- Как работает генерация видео на базе RNN
- Практические шаги: как создать свою модель генерации видео
- Какие инструменты и библиотеки используются при создании системы?
- Перспективы и вызовы генерации видео с помощью RNN
- Будущее генерации видео через RNN
- LSI-запросы по теме и дополнительные материалы
Генерация видео через рекуррентные нейронные сети: секреты искусственного творчества
Современный мир технологий стремительно развивается, и искусственный интеллект становится неотъемлемым инструментом в различных сферах жизни. Одной из наиболее захватывающих и перспективных областей является создание и генерация видео с помощью алгоритмов машинного обучения. Но как это происходит? Какие подходы существуют? И что такое RNN — рекуррентные нейронные сети — и как они помогают создавать движущиеся изображения? В этой статье мы подробно разберём все тонкости процесса генерации видео через RNN, поделимся нашим практическим опытом и расскажем о последних достижениях в этой области.
Что такое рекуррентные нейронные сети и почему они важны для генерации видео
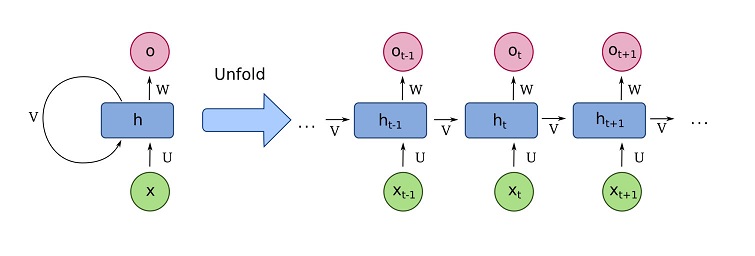
Рекуррентные нейронные сети, это особый тип искусственных нейронных сетей, предназначенных для обработки последовательных данных. В отличие от классических сетей, RNN способны учитывать «предыдущий опыт» и помнить информацию о предыдущих элементах последовательности, что делает их незаменимыми для задач с временной составляющей — таких, как речь, тексты, музыка и, конечно, видео.
Генерация видео — это сложный процесс, в ходе которого требуется моделировать не только статичные изображения, а ещё и динамику, переходы между кадрами, кликания объектов и даже изменение света. Именно здесь RNN проявляют свою уникальную способность «запоминать» и предсказывать последующие кадры, исходя из цепочки предыдущих.
Что такое рекуррентная нейронная сеть и почему она лучше подходит для генерации последовательных данных?
Рекуррентная нейронная сеть представляет собой архитектуру, которая обрабатывает входные данные пошагово, запоминая информацию на протяжении всей обработки. Это особенно важно для последовательных данных, где необходимо учитывать контекст, сделанный на предыдущих этапах, что делает RNN более подходящими для задач генерации видео по сравнению с обычными нейросетями.
Основные типы RNN для генерации видео
Существует несколько вариантов рекуррентных нейронных сетей, каждый из которых обладает своими особенностями и преимуществами в контексте видео-генерации:
- Стандартные RNN: Простая архитектура, но склонна к исчезающему градиенту при работе с длинными последовательностями, что ограничивает её использование для сложных задач.
- LSTM (Long Short-Term Memory): Более сложная модель, способная запоминать информацию на длительные промежутки времени. Идеальна для моделирования длительных видеопоследовательностей.
- GRU (Gated Recurrent Units): Более простая и гибкая альтернатива LSTM, которая также хорошо справляется с длинными зависимостями, занимает меньше ресурсов и быстрее обучается.
| Тип RNN | Преимущества | Недостатки |
|---|---|---|
| Стандартные RNN | Простота реализации | Засорение градиентов, ограниченность по длине последовательности |
| LSTM | Запоминание долгосрочной информации, высокая точность | Более сложная архитектура, ресурсоёмкость |
| GRU | Быстрее обучаются, меньше ресурсов | Иногда менее точные, чем LSTM |
Как работает генерация видео на базе RNN
Принцип работы системы, использующей RNN для генерации видео, состоит из нескольких этапов:
- Обучение на видеоданных — подбирается большая база видеозаписей, зачастую с учетом контекста или тематической направленности.
- Обработка и подготовка данных — видеоматериал разбивается на отдельные кадры, а также выполняется анимационная сегментация и подготовка последовательностей.
- Обучение модели — RNN "учится" предсказывать следующий кадр, основываясь на предыдущем, создавая цепочку допустимых переходов и движений.
- Генерация — при подаче начальных условий модель "прогоняет" последовательность, создавая новые кадры, которые сочетаются в целостное видео.
Сколько времени занимает обучение модели для генерации видео и какие ресурсы для этого нужны?
Обучение модели зависит от сложности задачи и объёма данных. Обычно это занимает от нескольких часов до нескольких недель. Необходимы мощные видеокарты (например, NVIDIA RTX или Tesla), большое количество оперативной памяти и стабильное хранилище для хранения данных и модели. Также важно иметь хорошо подготовленный датасет и оптимизированные алгоритмы обучения для повышения эффективности процесса.
Практические шаги: как создать свою модель генерации видео
Создание системы для генерации видео — это не только теоретические знания, но и конкретные практические умения:
- Подготовка данных: собираем видеоматериалы, разбиваем их на последовательные кадры и преобразуем для обучения.
- Выбор архитектуры модели: решаем, какой тип RNN использовать — LSTM или GRU, а также параметризуем сеть.
- Обучение модели: запускаем обучающие скрипты, корректируем гиперпараметры, следим за метриками эффективности.
- Тестирование и доработка: проверяем качество генерации, экспериментируем с начальным входом и настройками сети.
- Генерация новых видео: подаем начальные условия и запускаем модель для получения финального ролика.
Какие инструменты и библиотеки используются при создании системы?
| Инструменты | Описание |
|---|---|
| TensorFlow / PyTorch | Основные фреймворки для построения и тренировки нейросетевых моделей |
| OpenCV | Для обработки видеоданных, разбивки на кадры и визуализации результата |
| Keras | Удобная обертка для быстрого создания прототипов |
| CUDA | Для ускорения вычислений на GPU |
| Git | Версионный контроль кода и управление проектами |
Можно ли создавать реальные видеоролики с помощью RNN без специальных навыков программирования?
На сегодняшний день существуют платформы и готовые решения с интуитивным интерфейсом, позволяющие создать анимацию или видеоролик с минимальными знаниями программирования. Однако для разработки собственной сложной модели и оптимизации процесса всё равно потребуется базовое понимание нейросетей, программирования на Python и работы с фреймворками машинного обучения. Самое главное, желание учиться и экспериментировать.
Перспективы и вызовы генерации видео с помощью RNN
Несмотря на огромный потенциал, технология генерации видео на базе RNN сталкивается с рядом сложностей. В первую очередь — это вычислительные ресурсы и необходимость большого объема данных для обучения. Кроме того, качество создаваемых роликов зачастую все еще уступает реальности, особенно в ситуации сложного освещения, движений и взаимодействий объектов. Не менее важным является вопрос «этики»: создание поддельных видео, способных обмануть зрителя, порождает множество этических дилемм и регулирующих норм.
Однако научные институты, компании и независимые разработчики активно работают над преодолением этих препятствий, улучшая архитектуры и алгоритмы. Уже сегодня можно создавать видеоконтент, который неотличим от настоящего, а в ближайшие годы результаты станут еще более впечатляющими и доступными.
Будущее генерации видео через RNN
Представим, что через 5-10 лет появятся полностью автоматизированные системы, которые смогут создавать полноценные фильмы, видеоигры и обучающие ролики без участия человека. Возможно даже, что технологии позволят моделировать реальные сцены, создавая виртуальную реальность с невероятной точностью. Такой прогресс откроет новые горизонты для творчества, образования и бизнеса. Однако важно помнить и о необходимости этического регулирования, чтобы не допустить злоупотреблений и сохранения доверия к информации в цифровом пространстве.
Что нужно знать начинающему для работы с генерацией видео через RNN?
Важно обладать базовыми знаниями в области машинного обучения и нейронных сетей, уметь программировать на Python, разбираться в принципах работы фреймворков вроде TensorFlow или PyTorch, а также иметь представление о обработке видеоданных и алгоритмах компьютерного зрения.